What is Data Masking?
Data masking is a process of masquerading or hiding the original data with the changed one. In this, the format remains the same, and the value is changed only. This structurally identical, but the wrong version of the data is used for user training or software testing. Moreover, the main cause is to keep the actual data safe on the occasions where it is not required.
Although, the organizations have strict rules and regulations to keep their production data safe, however, in case of outsourcing of data, trouble may erupt. That’s why, most of the companies do not feel comfortable showing their data publicly.
Who uses Data Masking?
In order to comply with the General Data Protection Requirements (GDPR), companies have shown their interest in applying the data masking to ensure the security of their production data. According to the rules and regulations of the GDPR, all businesses that receive the data from EU citizens must be very well aware of the sensitivity of the issue and take some steps forward to avoid any inconvenience.
Therefore, it becomes inevitable for the companies that they mainstream to keep their sensitive data safe. Meanwhile, there are different kinds of data that can be used, but the following are most frequently used in business fields:
- Protected Health Information (PHI)
- Intellectual property (ITAR)
- Payment cards information PCI-DSS
All of the above examples lie under the obligation that must be followed.
Types of Data Masking
Data masking is a special technique that is applied to make your data non-accessible for non-production users. It is becoming popular among the organizations, and the reason behind this is an escalating cyber security threat. So, to cope with this menace of data, the masking technique is applied. It has different types that serve the same cause, but their way of proceeding remains different. Now, there are two major types, one is static, and the second one is dynamic.
-
Static Data Masking
In the case of static data masking, a duplicate of the database is prepared, and it is identical to the real database except for those fields that are to be faked or masked. This dummy content does not influence the working of the database at the time of real-world testing.
-
Dynamic Data Masking
In dynamic data masking, the important information is altered in real time only. So, the original data will only be seen by the users, while the non-privileged users could see the dummy data only.
Above are the main types of data masking, but the following types are also used.
-
Statistical data obfuscation
The production data of the company possesses different figures which are referred to as statistics. The masquerading of these statistics is called the statistical data obfuscation. Non-production users could never have an estimate of actual statistics in this type of data masking.
-
On the fly data masking
On the fly data masking is applied where environment-to-environment data transferring is done. This type is explicitly suitable for environments that perform continuous deployment for highly integrated applications.
Data Masking Tools
As we all know that technology is making persistent development on a daily basis, and solutions of different problems are getting modified. So, the tools that were available have added a new lot in them with even better efficiency and working quality. Therefore, here we have some of the latest data masking solutions or tools which are used to perform.
- DATPROF Data Masking tool
- IRI Field Shield (Structured Data Masking)
- Oracle Data Masking and Subsetting.
- IBM INFO SPHERE Optim Data Privacy
- Delphix
- Microsoft SQL Server Data Masking
- Information Persistent Data Masking
Further details of the tools have been given in the following table:
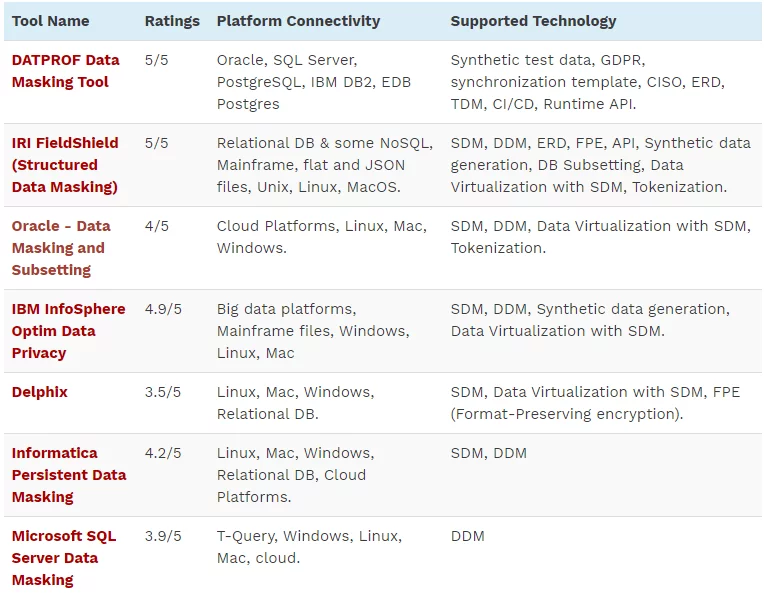
So, these are well-renowned tools, which may also be called as data masking solutions or data masking strategy.
Data Masking Techniques
There are numerous techniques that are applied to avail the opportunity. With the passage of time, the challenges are getting bigger, and the solutions are also becoming diverse.
Earlier, there were few techniques that were applied, but now there is a number of techniques that can be implemented. Moreover, the purpose of the user remains well served using all the given techniques, but functionalities might be different in case of different techniques. So, some of the most famous data masking techniques have been given below:
-
Shuffling
This one of the most frequently used technique. In this technique, the data is shuffled within the columns. But this is not used for high profile data, because shuffling can be reversed by deciphering the shuffling code.
-
Encryption
This is the most intricate technique. Usually, in encryption, the user has to produce the key for viewing the original data. But, handing over the key to someone, who is unauthorized to see the original data, might cause serious problems.
-
Number and date variance
The numeric change strategy is helpful for applying to money-related and date-driven fields.
-
Masking out
In this technique, the whole data is not masked out. There are certain statistics that are masked, so that original value cannot be figured out.
-
Nulling out or deletion
This technique is only used to avoid the visibility of different data elements. This is the simplest technique that can be used to apply the data masking. But, in order to find the visible data, the reverse engineering method can be applied. So, it is not that much suitable for the sensitive data.
-
Additional complex rules
Additional complex rules cannot be referred to as technique. But these are the rules that can be applied to any kind of the masking to make it more invincible against any intrusion from a non-authorized user. These rules include row internal synchronization rules, column internal synchronization rules, etc.
-
Substitution
This is the best suited masking technique. In this technique, any of the authentic statistical value is added to masquerade the original data. In this way, the non-authentic user does not find that value doubtful, and the data also remains preserved. This technique is applied in most of the cases where a sensitive information is to be hidden.
Data Masking Examples
There are different tools and software, and the examples also vary according to the tool or software used. Moreover, the masking of the data can be performed either statically or dynamically using every tool mentioned above. The result will be same in each case.
Earlier, most of the companies were out of this system, but for the time being, there are 114 big organizations only in the USA that are using the oracle data masking to make their information secure from non-production users. Moreover, now there will be a persistent explosion in the number of companies that would tend to adopt this technology, as security cannot be compromised.
Final Thoughts
Having gone through the whole article, you have comprehended the sensitivity and importance. So, in order to further ameliorate, here we are going to tell you about the best data masking practices as our final words:
-
Find Data
This is the first step in which you have to find the data that appears to be sensitive and needs to be masked.
-
Find the suitable Technique
After having seen the nature of the data, you may choose any of the technique that have been given above in the article. Keeping in view the circumstances, it will be easy to find a suitable masking technique.
-
Implementation of Masking
This is not going to work for a huge organization to use a single masking tool. But it needs to be done with a proper planning and diverse tools. Therefore, for having the best solutions out of your data masking, you must look into your future enterprise’s needs.
-
Test results of Data Masking
This is the final step. QA and testing are required to ensure the concealing arrangements to yield the desired outcomes.